This is “Search Engine Visibility”, section 13.3 from the book Online Marketing Essentials (v. 1.0). For details on it (including licensing), click here.
For more information on the source of this book, or why it is available for free, please see the project's home page. You can browse or download additional books there. To download a .zip file containing this book to use offline, simply click here.



13.3 Search Engine Visibility
Learning Objectives
- Understand the importance of visibility within search engines.
- Understand the basics of how to become visible to the search engines.
Search engine traffic is vital to a Web site; without it, chances are the site will never fulfill its marketing functions. It is essential that the search engines can see the entire publicly visible Web site, index it fully, and consider it relevant for its chosen keywords.
Here are the key considerations for search engine optimization when it comes to Web development and design.
Labeling Things Correctly
URLs (uniform resource locators), alt tagsTextual information that is displayed if an image cannot be displayed; used by search engines to determine what an image is., title tags, and metadataInformation that can be entered about a Web page and the elements on it that provides context and relevancy information to search engines; these used to be an important ranking factor. all describe a Web site and its pages to both search engine spiders and people. (And don’t worry: these words are all described for you in what follows.) Chances are, clear descriptive use of these elements will appeal to both.
URLs
URLs should be as brief and descriptive as possible. This may mean that URLs require server-sideOperations that take place on the server. rewriting so as to cope with dynamic parametersThe elements of a URL that are dynamically generated. You can identify them by question marks and ampersands in a URL. in URLs. Does that sound a little heavy? The examples below should make this clearer.
Comparison of URLs for a Product
The following is a comparison of the URLs for Diamante Dog Collars, an imaginary product for sale on two imaginary Web sites:
- DogToys.com. http://www.dogtoys.com/index.html?dir=423&action=product&pid=1201
- CoolPuppies.co.uk. http://www.coolpuppies.co.uk/Products/Collars/Fancy/DiamanteDogCollars.htm
The first example has dynamic parameters—these are shown by the question mark and the ampersand—and uses categories that make sense to the database (e.g., pid=1201), but they make little sense to the user. Dynamic parameters are so called as they change depending on the information being requested. Next time you use a search engine to search for information, take a look at the URL and see if you can spot the dynamic parameters.
The second example is far more user friendly and clearly indicates where in the site the user is. You even start getting a good idea of the architecture of the Web site from just one URL.
More than two dynamic parameters in a URL increase the risk that the URL may not be spidered. The search engine would not even index the content on that page.
Lastly, well-written URLs can make great anchor text. If another site is linking to yours and they use just the URL, the search engine will do a better job of knowing what the page is about if you have a descriptive URL.
Alt Tags
Have you ever waited for a page to load and seen little boxes of writing where the images should be? Sometimes they say things like “topimg.jpg” and sometimes they are much clearer and you have “Cocktails at sunset at Camps Bay.”
Since search engines read text, not images, descriptive tags are the only way to tell them what the images are, but these are still essentially for users. Text readers for browsers will also read out these tags to tell the user what is there. Meaningful descriptions certainly sound a lot better than “image1,” “image2,” and “image3.”
Title Attributes
Just as you can have the alt tag on an image hypertext markup language (HTML)The code that is used to write most Web sites. element, you can have a title attribute on almost any HTML element—most commonly on a link. This is the text that is seen when a user hovers over the element with the mouse pointer. It is used to describe the element or what the link is about. As this is text, it will also be read by search engine spiders.
Title Tags
Title tags, or what appears on the top bar of your browser, are used by search engines to determine the content of that page. They are also often used by search engines as the link text on the search engines results’ page, so targeted title tags help drive click-through rates. Title tags should be clear and concise (it’s a general rule of thumb that all tags be clear and concise, you’ll find). Title tags are also used when bookmarking a Web page.
Figure 13.4
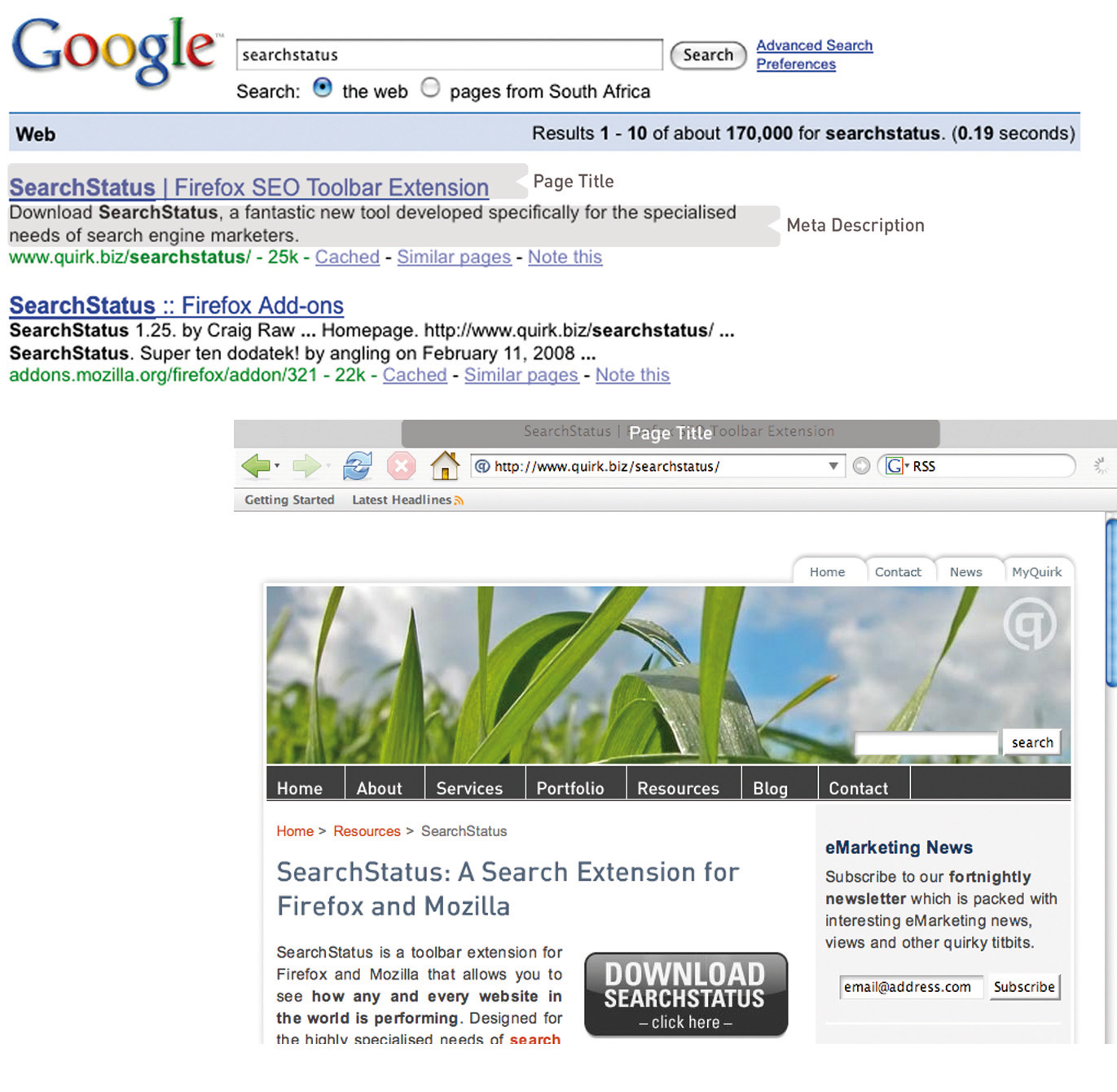
The title tag appears in the browser and on the search engine results page (SERP), and the meta description can appear on the SERP as well.
Meta Tags
Meta tags are where the developer can fill in information about a Web page. These tags are not normally seen by users. If you right click on a page in a browser and select “view source,” you should see a list of entries for “<meta name=.”
These are the metadata. In the past, the meta tags were used extensively by search engine spiders, but since so many people used this to try to manipulate search results, they are now less important. Metadata now act to provide context and relevancy rather than higher rankings. However, the meta tag called “description” often appears on the search engine results page (SERP) as the snippet of text to describe the Web page being linked to. This is illustrated in Figure 13.4. If the description is accurate, well written, and relevant to the searcher’s query, these descriptions are more likely to be used by the search engine. And if it meets all those criteria, it also means the link is more likely to be clicked on by the searcher.
Search Engine–Optimized Copy
When it comes to Web development, the copy that is shown on the Web page needs to be kept separate from the code that tells the browser how to display the Web page. This means that the search engine spider can discern easily between what is content to be read (and hence scanned by the spider) and what are instructions to the browser. A cascading style sheet (CSS)An approach to Web design that aims for lightweight code and standards-compliant Web sites. can take care of that and is covered further in this chapter.
The following text styles cannot be indexed by search engines:
- Text embedded in a Java application or a Macromedia Flash file
- Text in an image file (that’s why you need descriptive alt tags and title attributes)
- Text only accessible after submitting a form, logging in, and so on
If the search engine cannot see the text on the page, it means that it cannot spider and index that page.
If an XML (extensible markup language) file is used for the content in a Macromedia Flash file, then the content can be easily read by search engine spiders.
Information Architecture
Well-organized information is as vital for search engines as it is for users. An effective link structure will provide benefits to search rankings and helps to ensure that a search engine indexes every page of your site.
Make use of a site map, linked to and from every other page in the site. The search engine spiders follow the links on a page, and this way, they will be able to index the whole site. A well-planned site map will also ensure that every page on the site is within a few clicks of the home page.
There are two site maps that can be used: an HTML site map that a visitor to the Web site can see, use, and make sense of and an XML (extensible markup language)A standard used for creating structured documents. site map that contains additional information for the search engine spiders. An XML site map can be submitted to search engines to promote full and regular indexing. Again, a dynamically generated site map will update automatically when content is added.
Using a category structure that flows from broad to narrow also indicates to search engines that your site is highly relevant and covers a topic in depth.
Canonical Issues: There Can Be Only One
Have you noticed that sometimes several URLs can all give you the same Web page? For example, refer to the following:
- http://www.websitename.com
- http://websitename.com
- http://www.websitename.com/index.html
All the above can be used for the same home page of a Web site. However, search engines see these as three separate pages with duplicate content. Search engines look for unique documents and content, and when duplicates are encountered, a search engine will select one as canonical, and display that page in the SERPs (search engine results pages). However, it will also dish out a lower rank to that page and all its copies. Any value is diluted by having multiple versions.
Lazy Webmasters sometimes forget to put any kind of redirect in place, meaning that http:// websitename.com doesn’t exist, while http://www.websitename.com does. This is termed “Lame-Ass Syndrome” (LAS) by Quirk, a fitting moniker.
Having multiple pages with the same content, however that came about, hurts the Web site’s search engine rankings. There is a solution: 301 redirects can be used to point all versions to a single, canonical version.
Robots.txt
A robots.txt file restricts a search engine spider from crawling and indexing certain pages of a Web site by giving instructions to the search engine spider, or bot. This is called the Robots Exclusion ProtocolA protocol used to indicate to search engine robots which pages should not be indexed.. So, if there are pages or directories on a Web site that should not appear in the SERPs, the robots.txt file should be used to indicate this to search engines.
If a search engine robot wants to crawl a Web site URL—for example, http://www.websitename.com/welcome.html—it will first check for http://www.web sitename.com/robots.txt.
Visiting the second URL will show a text file with the following:
- User-agent: *
- Disallow: /
Here, “User-agent: *” means that the instruction is for all bots. If the instruction is to specific bots, it should be identified here. The “Disallow: /” is an instruction that no pages of the Web site should be indexed. If there are only certain pages or directories that should not be indexed, they should be included here.
For example, if there is both an HTML and a PDF (portable document format) version of the same content, the wise Webmaster will instruct search engine bots to index only one of the two to avoid being penalized for duplicate content.
The robots.txt file is publicly accessible, so although it does not show restricted content, it can give an idea of the content that a Web site owner wants to keep private. A robots.txt file needs to be created for each subdomain.
Here is a robots.txt file with additional information.
Figure 13.5

Instructions to search engine robots can also be given in the meta tags. This means that instructions can still be given if you only have access to the meta tags and not to the robots.txt file.
Make Sure It’s Not Broken
Make sure that both visitors to your Web site and search engines can see it all by following these guidelines:
- Check for broken links—anything that you click that gives an error should be considered broken and in need of fixing.
- Validate your HTML and CSS in accordance with World Wide Web Consortium (W3C)Oversees the Web Standards project. guidelines.
- Make sure all forms and applications work as they ought to.
- Keep file size as small as possible and never greater than 150 kilobytes for a page. It ensures a faster download speed for users and means that the content can be fully cached by the search engines.
Key Takeaways
- One of the foundations of a successful site is search engine visibility.
- It is important to make sure everything on the site is labeled correctly.
- It is important to write copy optimized for search engines.
- Information architecture is important on a site, as content needs to be presented in a way that makes sense for the user.
- Make sure there aren’t multiple URLs for one set of content. This will dilute the rank.
- Robots can be used if a certain Web page shouldn’t appear in the SERPs.
- Make sure your site is fully functional and that it follows best practices.
Exercises
- Visit a retail Web site, such as http://www.amazon.com, and a news Web site, such as http://www.news.bbc.co.uk, and identify the common page elements of each. What elements are common to both Web sites?
- Why do you think Web site owners would want to keep search engines out of certain pages, or even whole Web sites?
- What are the differences between an HTML site map and an XML site map?